[Review] Patch SVDD (1부: Anomaly detection 개요)
최근에 anomaly detection에 관련된 페이퍼들을 읽을 일이 많이 있었는데, 개인적으로도 하나씩 다시 정리해볼 겸 논문 리뷰 글을 주기적으로 올릴 생각이다.
paper link: arxiv.org/pdf/2006.16067.pdf
github (PyTorch): github.com/nuclearboy95/Anomaly-Detection-PatchSVDD-PyTorch
이번 논문은 Patch SVDD로, 새로운 image anomaly detection method를 제시한다. 자세한 내용을 설명하기 이전에, 여기서 다루고자 하는 문제인 image anomaly detection이 무엇인지에 대해 먼저 짚고 넘어가자.
(편의를 위해 각종 definition과 notation은 논문의 내용을 빌린다)
Problem formulation
Anomaly detection
Anomaly detection은 어떤 input 데이터에 대해, 이 데이터 인스턴스가 anomaly인지 아닌지 binary decision을 내리는 문제라 표현할 수 있다. 그렇다면 여기서 "anomaly" 가 어떤 데이터를 뜻하는가.. 하면 사실 anomaly의 정의에 대해서 완벽한 컨센서스는 없다.
일반적으로 서베이 등을 찾아 보면 "다른 대다수의 데이터와 확연히 다른 양상을 보이는 데이터 인스턴스" 정도가 최선의 표현었던 것으로 보인다. 사실 알고리즘 단에서 실제로 구분해 내야 하는 소위 사람이 anomaly라 생각하는 데이터 는 그 특성이 데이터 도메인과 어플리케이션에 따라 천차만별이기 때문에, 결국에는 골라내기를 원하는 데이터 인스턴스에 맞추어 anomaly를 각자 정의해 문제 정의에 사용하는 것 같다. 적어도 본인은 그렇게 생각하고 있다.
본 페이퍼에서는 anomaly의 범위를 image 상의 결함 (defect) 으로 좁혀 놓고 문제 정의를 시작하고 있다.

일반적으로 anomaly detection은 데이터 인스턴스에 대해 anomaly score를 계산하는 어떤 함수를 세우고, 이 함수로 얻어낸 데이터 인스턴스 별 score 값을 thresholding 하는 식으로 진행된다. Threshold를 넘는 스코어를 가지는 데이터는 anomaly로, 넘지 않는 데이터는 non-anomaly로 분류한다는 것이다.
정확히 어떤 형식의 인풋이 들어가 어떤 형태의 score를 계산하는지의 디테일은 달라질 수 있다. 예를 들어 시간에 따라 연속으로 들어오는 데이터에 대해서, time t 에서의 데이터 인스턴스의 anomaly 여부를 판단하는데 t-T ~ t 까지의 데이터가 이용될 수 있다.
하지만 큰 맥락에서의 방법론은 서로 크게 다르지 않으며, 글 맨 아래에 링크를 걸어둔 서베이들을 참고하면 자세한 이해에 도움이 될 것이다.
AUROC
본 페이퍼에는 이미지별로 스칼라 형태의 anomaly score를 얻어내는 anomaly score function을 정의해, image anomaly detection 방법론으로써 사용한다.
(아직 티스토리에서 in-line 레이텍 구문을 어떻게 작성하는지 몰라 일단 말로 때우고 있다... 좀 더 알아보고 난 후 수정할 계획이다)
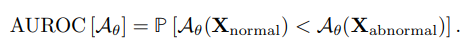
그럼 이 스코어를 thresholding 해 얼마나 anomaly인지 아닌지를 잘 구분해 낼 수 있는가를 평가하는 성능 지표가 필요할 텐데, 흔히 쓰이는 도구가 area under the receiver operating characteristic curve (AUROC) 이다.

정말 간단하게 설명하자면.. 데이터들을 스코어 축 상에 흩뿌려 놓아 그 분포를 보고 있다고 해 보자 (위 사진의 왼쪽 위 그림 참고). 일정 스코어 값을 기준으로 한 쪽은 0으로, 한 쪽은 1로 라벨링 했을 때 (가운데 검은 수직 선), ground-truth 라벨과 일치하도록 데이터를 분류해 내기가 얼마나 쉬운 지를 정량적으로 측정하는 지표라 이해하면 쉽다.
Anomaly detection 문제로 끌어와, 위 사진의 분포도에서 왼쪽 언덕이 실제 non-anomaly 데이터 인스턴스의 스코어 분포, 오른쪽 언덕이 실제 anomaly 인스턴스의 스코어 분포라 해 보자.
만약 두 언덕이 스코어 축 상에서 거의 겹쳐 있다면, thresholding을 통해 anomaly를 구분해 내는 것이 의미가 없을 것이고 (랜덤 분류와 다르지 않다), 두 언덕이 축 상에서 완벽히 떨어져 있다면 대충 언덕 사이 중간 지점에 선을 긋는 것 만으로도 anomaly와 non-anomaly가 쉽게 나누어질 것이다.
Anomaly score 함수를 잘 구성할수록 두 언덕은 스코어 축 상에서 멀리, 구분해 내기 쉽도록 떨어져 있을 것이고 (이상적인 케이스), 이 구분의 난이도가 AUROC 값으로 표현된다. AUROC=0.5가 위에서 말한 anomaly와 non-anomaly가 스코어 축 상에서 구분이 되지 않는 경우, AUROC=1.0이 스코어 축 상에서 완벽히 분류해 낼 수 있는 경우이다.
만약 anomaly 라벨이 image 단위로 매겨지는 것이 아니라 이미지 안의 픽셀 단위로 매겨져 있고, 픽셀 단위로 anomaly 여부를 분류해 내는 문제가 되면 anomaly detection이 아닌 (image) anomaly segmentation 문제가 된다. AUROC을 구하는 방식 자체는 이미지 단위에서와 동일하게 적용될 수 있다.
처음에는 글 하나에 다 넣어 보려 했는데, 생각보다 정리해야 할 내용이 불어나는 바람에 분절해서 글을 올리게 되었다. 이후에 글이 쌓이면 기존 글들을 참조하는 식으로 설명을 줄이고 컴팩트하게 작성할 계획이다.
아래는 추가적으로 참고할 만한 자료들이다.
이것들에 대해서도 따로 리뷰를 하고 싶지만 어찌 될 진 모르겠다.
References
DEEP LEARNING FOR ANOMALY DETECTION: A SURVEY