[Review] DensePose From WiFi
paper link: https://arxiv.org/pdf/2301.00250.pdf

Introduction
본 논문에서는 기존에 RGB 이미지나 레이더, 라이다 데이터를 이용해 다루어지던 3D human pose estimation 문제를 1D 센서인 WiFi 안테나와 그것을 이용해 측정한 WiFi 신호를 이용해 딥러닝 기반으로 해결하는 방법을 제시한다.
Occlusion이나 환경의 변화에 민감한 이미지 데이터나, 값비싼 하드웨어가 필요하며 공공 공간에서 사생활 침해의 우려가 있는 레이더, 라이다 데이터와는 달리 저렴하고 장비 자체의 접근성이 좋으며 사생활을 보장하는 방식으로 기존의 이미지 기반의 pose estimation 성능 수준을 달성할 수 있다고 주장한다.
Methodology
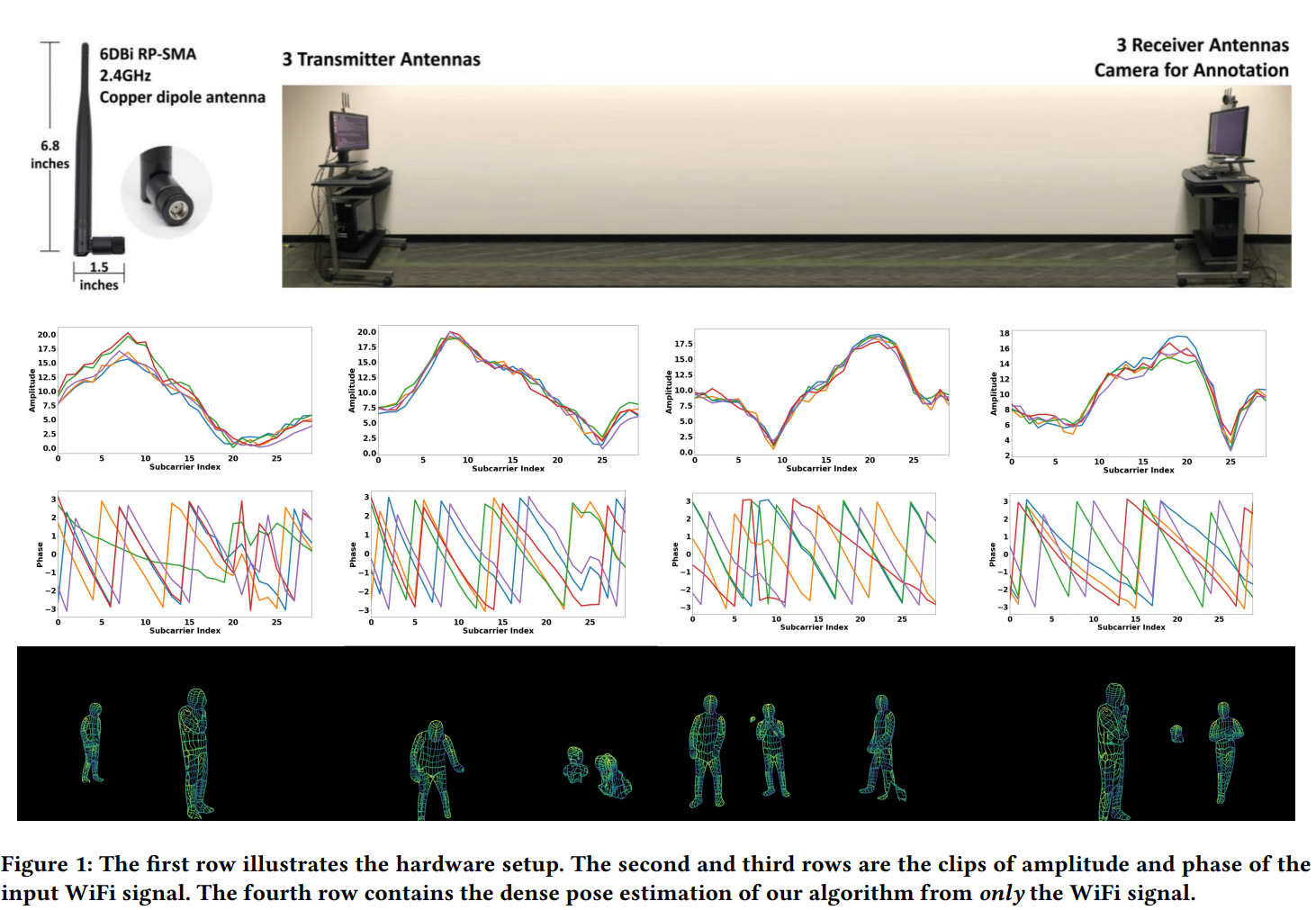
3개의 WiFi 송신기와, 3개의 정렬된 수신기가 존재하는 세팅에서, 여러 명의 사람과 여러 사물이 자유롭게 놓인 상황 하에서 사람들의 dense human pose correspondence를 추정하는 문제를 풀고 있다.
여기서 dense human pose correspondence란, 이미지나 비디오 프레임에서 몸통이나 머리, 팔과 같은 사람의 body part를 매칭시키는 태스크를 의미한다.
Data
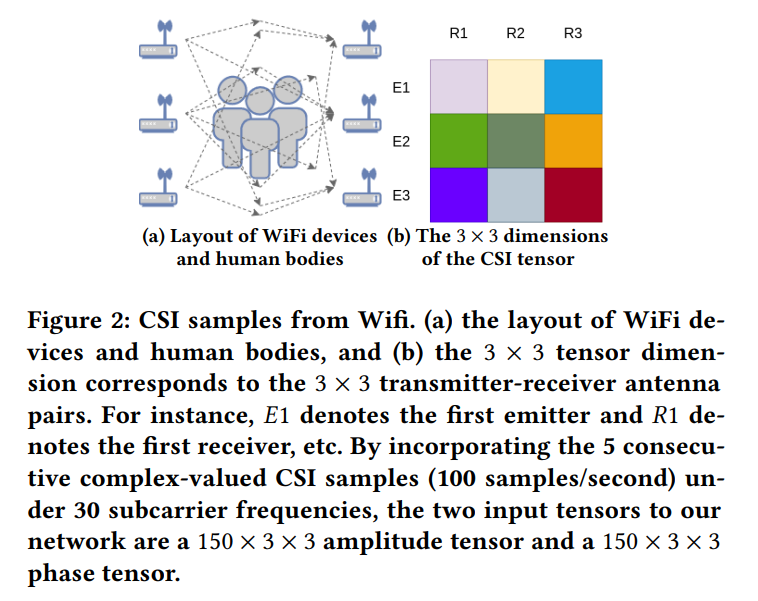
데이터로는 CSI 매트릭스라는 것이 사용된다. 3개의 송신기 출력과 3개의 수신기 입력 결과가 조합되어 3x3의 real value matrix와 3x3의 imaginary value matrix가 하나의 CSI 데이터를 이룬다. 2.4GHz 주변으로 linear하게 놓여진 30개의 frequency 각각에 대해 한 번씩 측정되었으며, CSI 데이터는 100Hz로 샘플링 되는데 여기서 5개의 연속된 CSI 측정값을 사용해 결과적으로 150x3x3 의 진폭 텐서와 150x3x3 의 위상 텐서가 데이터로써 이용된다.
네트워크의 아웃풋으로는 17개의 키포인트에 대한 17x56x56 의 키포인트 히트맵 텐서와, 24개의 body part와 배경에 대한 25x112x112의 UV map이 출력된다. 여기서 UV map이란 3D 물체를 2차원에 표현한 것으로, 2차원 표현의 각 지점이 3차원 공간의 어느 위치에 매핑되는지를 나타내고 있다고 보면 된다.
Feature extractor - Modality Translation Network
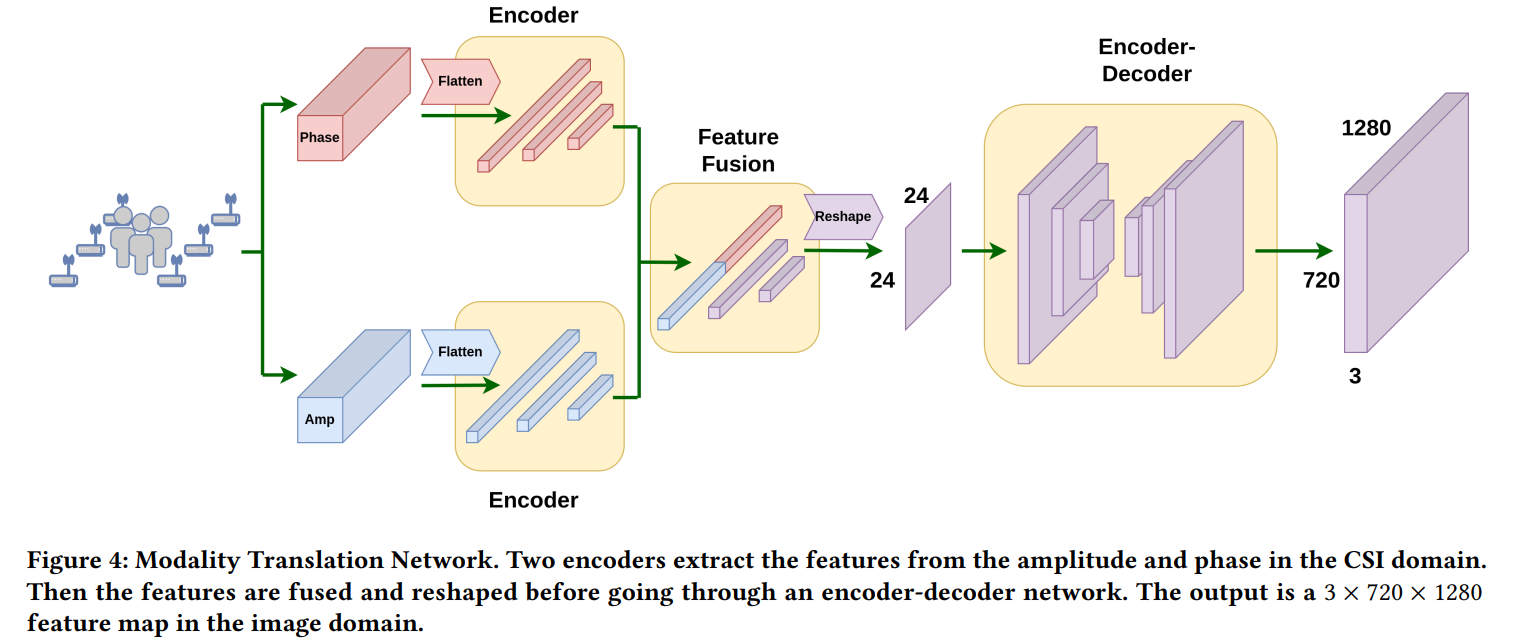
진폭과 위상 데이터 텐서는 벡터의 형태로 flatten되어 각각 multi-layer perceptron 구조의 인코더에 태워진다. 그 후, 이 feature들이 concat되어 추가적인 feature extraction 과정을 거친 후 24x24 모양 이미지의 형태로 reshape 된다. 이는 latent space feature를 spatial domain으로 옮겨놓기 위한 작업이다.
다시 CNN 기반의 인코더와 디코더를 거치면서 6x6 사이즈까지 줄어들었다가 결과적으론 3x720x1280 사이즈의 RGB 이미지와 동일한 형태의 spatial feature representation을 얻게 된다.
이 이후에는, 기존의 image 기반의 dense pose estimation 방법론이 그대로 사용된다 (DensePose-RCNN). 결국 이 논문에서는 1D WiFi 데이터를 전처리해 이미지처럼 사용할 수 있는 RGB 이미지 형태의 feature로 가공하는 방법을 메인으로 제시했다고 볼 수 있다.
WiFi-DensePose RCNN
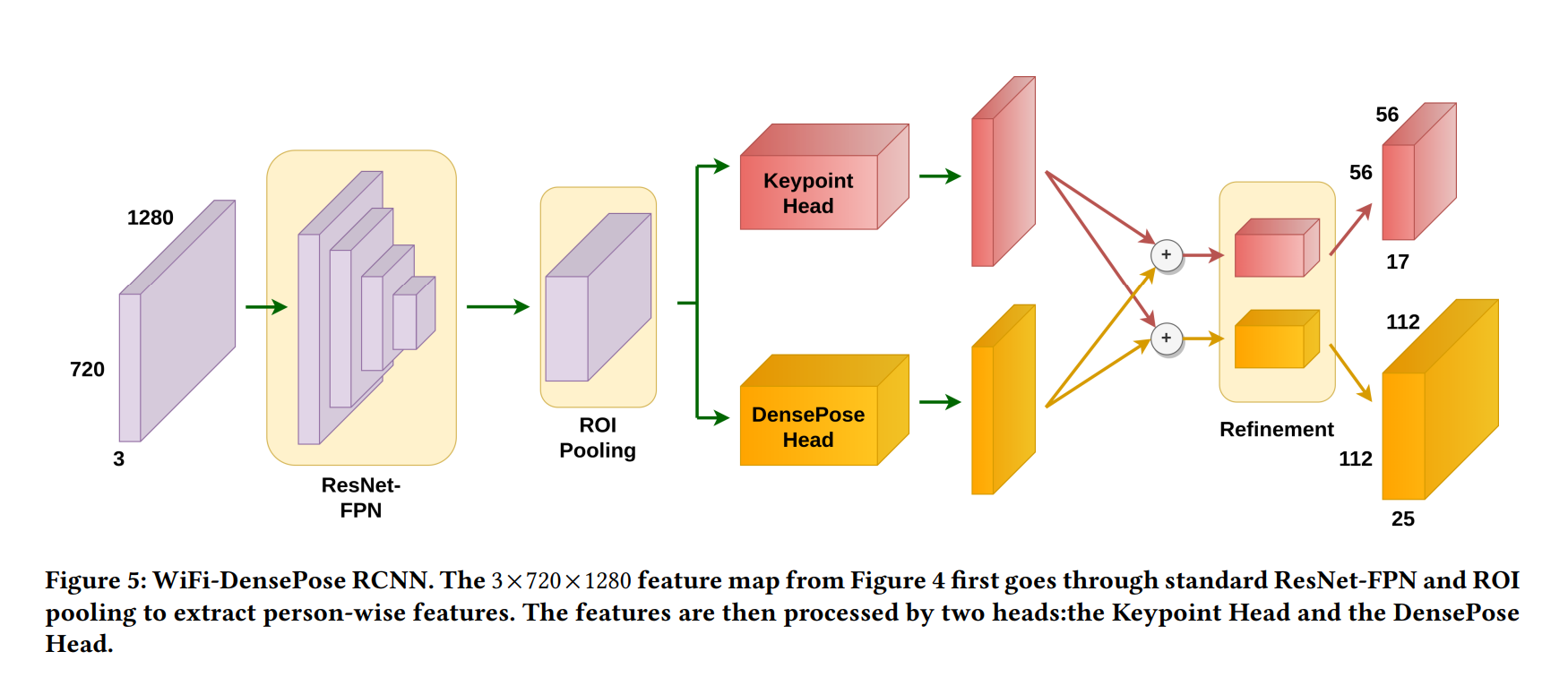
합쳐진 모델을 WiFi-DensePose RCNN이라 지칭하며, 자세한 아키텍쳐는 위 그림에 나와 있다. Dense pose에 비해서 상대적으로 추정이 쉬운 keypoint를 동시에 추정하도록 해, pose prediction의 추정 결과가 joint와 같은 keypoint 예측으로부터 크게 벗어나지 않도록 보조하고 있다.
Transfer learning
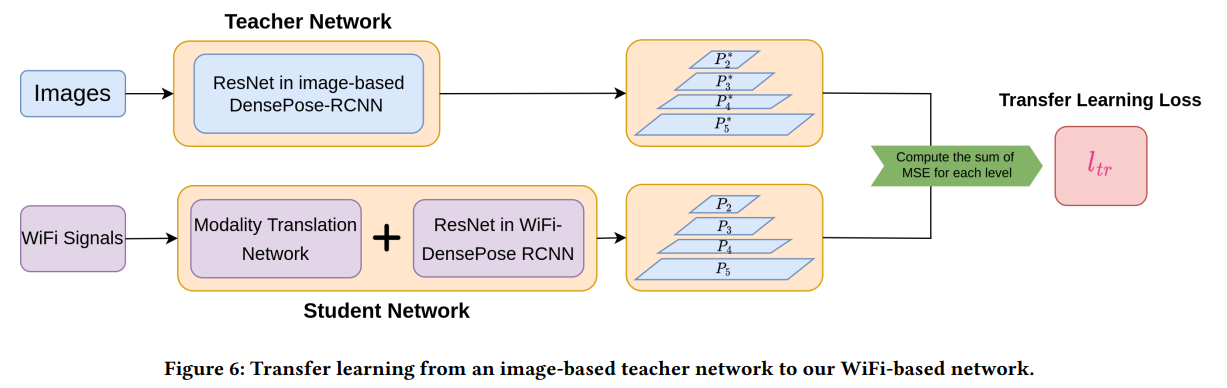
추가적으로 학습 속도를 높이기 위해 image-base의 DensePose-RCNN 모델의 knowledge를 WiFi-base 모델로 trasfer 하는 접근을 취하고 있다. 이미지, 그리고 같은 조건에서 측정된 CSI 데이터를 이용해 student network 가 (WiFi-base) teacher network (Image-base) 의 feature를 각 레이어별로 따라가도록 유도한다.
Results

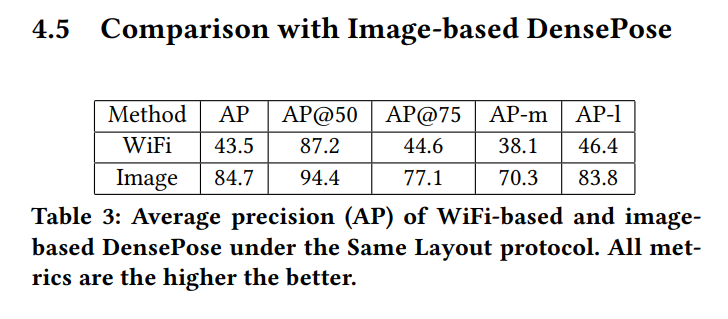
결과적으로, 기존의 Image based 접근과 비교해 수치적으로 더 나으면서 정성적으로도 괜찮은 결과를 얻을 수 있었다고 리포트 하고 있다.
위 표에서 AP는 average precision 메트릭의 약자로, human bounding box의 추정 정확도를 보여준다. 페이퍼에서는 추가적으로 dpAP· GPS와 dpAP· GPSm 메트릭을 사용해 pose estimation의 정확도를 추가적으로 리포트 하고 있다.
아래는 참고할 만한 페이지들이다.
References
Understanding of Channel State Information (CSI)
https://link.springer.com/chapter/10.1007/978-981-16-5658-3_2
mAP (mean Average Precision) for Object Detection
https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173
DensePose-RCNN System