![[Review] Patch SVDD (2부: Method & experiment)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F3NMSE%2Fbtq2hJXsTAz%2F9AK4dml9Kj8GfslX4nvTe1%2Fimg.png)
이전 포스트: Patch SVDD Review 1부
paper link: arxiv.org/pdf/2006.16067.pdf
github (PyTorch): github.com/nuclearboy95/Anomaly-Detection-PatchSVDD-PyTorch
지난 번 포스트에 이어서 리뷰를 작성한다.
1부에서는 논문에서 풀고자 했던 문제인 (image) anomaly detection과 anomaly segmentation, 그리고 성능 지표인 AUROC에 대해서 간략히 알아봤다.
이번에는 논문에서 제시된 새로운 anomaly detection 방법론과 그 결과에 대해 정리할 예정이다.
(In-line LaTeX 구문을 써 봤는데 모바일 버전에선 제대로 보여지지 않는 것 같다! 방법을 찾으면 추후 수정할 예정이다)
Method
Baseline: Deep SVDD
Patch SVDD anomaly detection 방법론은 Deep SVDD 알고리즘을 기반으로 하고 있다. 아래의 그림을 보자.

Deep SVDD는 데이터의 normality를 배우기 위한 방법론 중 하나로, 다음과 같은 접근을 취하고 있다.
Normal (non-anomalous) 클래스로 지정된 어떤 데이터셋이 있다고 가정하자 (왼쪽 그림의 검은색 포인트). 그리고 각각의 데이터를 처리해 어떤 유용한 meaning을 가지는 공간으로 옮겨 주는 feature extractor가 있다고 하자. 여기서 데이터가 살고 있는 공간을 data space $\mathcal{X}$, 데이터가 feature extractor를 통과해 만들어진 데이터의 feature $\phi(x;\mathcal{W})$ (오른쪽 그림의 포인트) 가 놓여진 공간을 feature space $\mathcal{F}$ 라 하자.
Feature space $\mathcal{F}$ 상에서 반경 $R$ 과 중심점 $c$ 를 가지는 어떤 구를 정의했을 때, deep SVDD의 loss (손실함수)는 다음과 같이 정의된다.
Normal 클래스 데이터가 주어졌을 때, feature extractor $\phi(\cdot;\mathcal{W})$ 를 통과한 데이터들이 feature space 상에서의 포인트 $c$ 근처에 놓여지도록 유도하고 있다.
이 방법론의 핵심 가정은.. 데이터들을 normality를 잘 표현하는 feature space 상의 점 $c$ 근처로 모으도록 (반경 $R$ 안에) feature extractor를 학습 시키면, normality 특성을 공유하지 않는 out-of-class 데이터는 점 $c$ 에서 먼 곳에 찍힐 것이다, 라는 것이다.
Anomaly detection 문제로 가져오면, 테스트 이미지에서 얻어낸 feature vector가 점 $c$ 에서 얼마나 멀리 떨어져 있는가를 anomaly score 함수로 이용하게 된다.
Deep SVDD의 더 자세한 디테일과, (또다시) 이 알고리즘의 기반이 되는 고전 머신러닝 방법론인 SVDD (Support Vector Data Description) 에 대해서는 글 맨 아래에 걸어놓은 링크들을 참고하자.
저자들은 이 방법론을 modify 한 Patch SVDD 방법론을 제시한다. 한번 디테일을 살펴보도록 하자.
New method: Patch SVDD
이전의 식에서 조금 notation을 바꿔, 기존 deep SVDD의 loss를 다음과 같이 표현해 보자.
Patch SVDD의 loss는 다음과 같이 정의된다.
여기서 $p_i$ 는 이미지 내의 patch (box 형태의 더 작은 region) 를, $p_{i'}$ 는 $p_i$ 와 인접한 patch를 지칭한다. 두 방법론의 차이는 아래의 그림에서 잘 표현된다.
Deep SVDD는 이미지 전체의 feature 들을 하나의 점으로 모았다면, Patch SVDD는 이미지 대신 더 작은 사이즈의 이미지 patch의 feature 각각을 feature space 상에서 모으되, 특정한 점을 향해서가 아니라 서로 공간적으로 인접한 patch끼리 모이도록 유도한다는 것이 차이점이다.
이미지 plane 상에서 거리가 가까운 patch 쌍이 거리가 먼 patch 쌍보다 의미적으로 공유하는 특성이 더 많을 것이라는 가정이며, 실제로 이미지 상에서 물체(object)나 배경(background)은 spatial하게 연결된 영역에 걸쳐 나타나므로 꽤 합리적인 설계라 볼 수 있다.
이 방법론의 장점은 우선 feature를 한 점으로 explicit하게 모으지 않기 때문에, normality 클래스 내에서 개별 데이터 사이에 서로 공유하는 특성이 적은 경우(multi-modal data / high intra-class variance) 에 대응을 할 수 있다는 점이다.
위 그림의 오른쪽 사진에서처럼, 이미지 내부의 foreground나 background 영역의 patch, 즉 이미지 단위로는 똑같은 normal class 이지만 개별 패치 단위로는 다양한 appearance가 나타날 수 있는 경우에 특히 효과적이다.
그리고 이미지가 아닌 smaller patch를 데이터로 이용하는 방식에서도 몇 가지 이점이 있는데, 우선 anomaly detection의 단위가 이미지에서 patch로 내려가면서 anomalous region에 대한 localization 능력이 향상되었다.
이미지 단위의 detection에서는, 특별히 score map이나 attention map 등을 따로 구할 수 있는 프레임워크가 아닌 이상 이미지 단위의 anomaly score만을 구할 수 있고, 이 스칼라 값은 이미지의 어느 부분 때문에 높은 anomaly score를 얻었는지에 대한 단서를 제공하지 않는다.
하지만 patch 단위의 detection을 하게 되면서, 이미지의 small region 단위로 anomaly score 값을 얻게 되고 자연스럽게 이미지의 어느 영역이 가장 anomalous 한지에 대한 정보를 얻을 수 있다.
또한 small defect로 표현되는 anomaly를 탐지해 내는 데 있어, 이미지 전체로부터 스코어를 얻어내는 방식에 비해서 region 별로 세세하게 탐지를 하는 방식 덕분에 detection 성능을 더욱 끌어올릴 수 있다고 주장한다.
Feature extractor
Hierarchical encoding
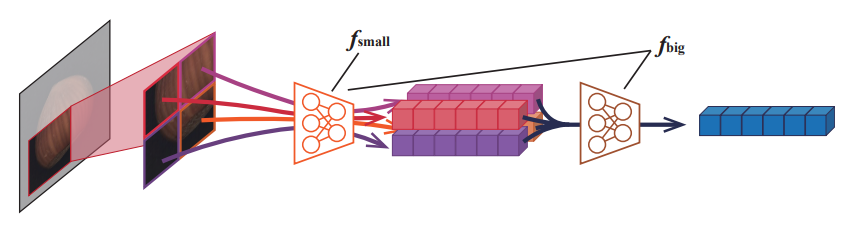
Anomaly가 이미지 상의 작은 defect 라는 것은 어느정도 예상하고 있어도, 이 defect가 정확히 어느 정도의 크기를 가지는 지는 정확히 파악할 수 없다. 이 문제를 해결하기 위해, 본 논문에서는 서로 다른 인식 범위(receptive field) 를 가지는 feature extractor를 사용한다.
각 patch에 대해서, small extractor는 2x2 그리드로 나눠진 패치에 대해 feature extraction을 수행한 후, 그것들을 합쳐 패치 $p$의 feature로 사용한다 (디테일을 놓쳤을 수도 있지만, 뭔가 방식이 적혀있지 않다.... 아마 concatenate 해 하나의 벡터로 만드는 것으로 추정한다).
Big extractor는 위에서 얻어낸 합치기 이전의 feature tensor를 한번 더 별개의 feature extractor에 forward 시킴으로써 더 큰 receptive field를 가지는 feature를 얻는다. 위의 그림을 참고하자.
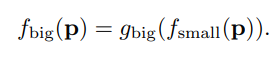
이 big extractor와 small extractor로 얻어낸 feature들은 따로 합치지 않고, 둘 다 patch의 feature로써 개별적으로 이용하게 된다. 이미지 패치 하나 당 big scale의 receptive field를 가지는 feature 하나, 그리고 small scale의 feature 하나를 따로따로 구한다고 이해하면 된다. 이후 SVDD를 통한 anomaly score 계산은 각 feature에 대해 별개로, 총 두번 수행해 그 결과를 합치게 된다.
이런 식의 hierarchical encoding을 통한 multi-scale feature extraction 방법론의 유효성은 이후에 실험적으로 검증하고 있다.
Self-supervised learning
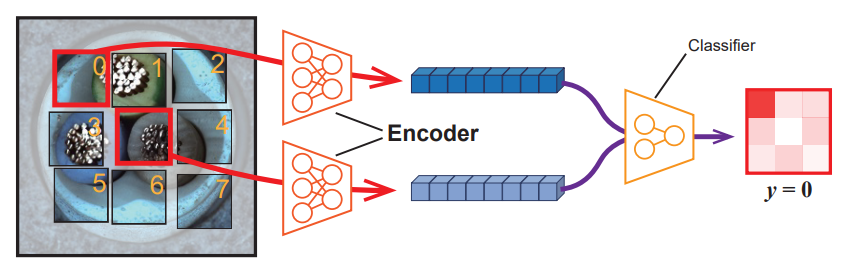
그리고 feature extractor(encoder)가 좀 더 유의미한 정보를 patch로부터 추출할 수 있도록, patch 간의 상대적인 위치 관계를 분류하는 self-supervised learning task를 보조적인 태스크로 사용했다.
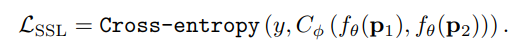
두 인접 패치로부터 얻은 feature vector 두 개를 인풋으로 받아, patch 사이의 상대적인 위치 관계를 분류하는 classifier를 만들고, 분류 태스크의 loss 함수를 기존 loss 함수와 weighted sum을 함으로써 최종적으로 사용할 loss 함수가 만들어지게 된다. 아래의 식을 참고하자.
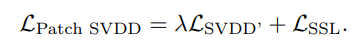
저자들은 이런 보조 태스크를 통해 feature extractor가 patch로부터 유의미한 정보를 추출하도록 유도하는 것이 anomaly detection 성능을 증강시킬 것이라 주장한다.
사족으로, 사실 이런 self-supervised learning task를 병행시킴으로써 얻고자 하는, 그리고 실제로 얻는 효과가 조금 더 자세히 분석이 되었으면 좋겠다는 생각도 든다. 현재는 단순히 결과론적인, 실험적인 결과들을 통해서만 정당성을 얻고 있는 느낌이라 찜찜한 느낌을 지울 수가 없다.
Anomaly map & score
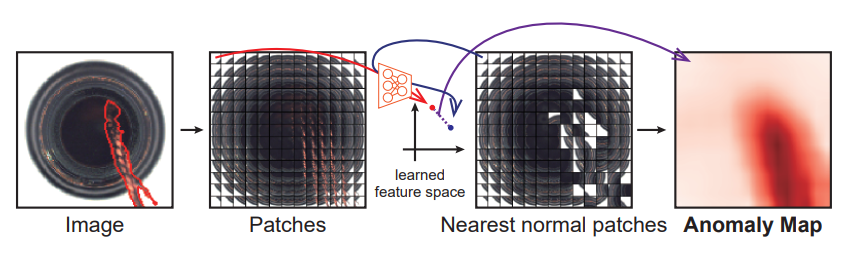
이렇게 학습시킨 feature extractor를 이용해 patch 단위로 anomaly 스코어를 계산하고, 이를 통해 최종적인 anomaly map을 이미지마다 구해낸다. 기존의 SVDD는 이미지 단위로 얻어낸 feature가 center $c$ 에서 얼마나 떨어져 있나를 스코어로 이용했지만, Patch-SVDD는 특정한 중심점 $c$ 가 존재하지 않아 이 방법론을 그대로 사용할 수 없다.
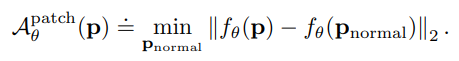
대신, 주어진 모든 정상 이미지에 대해서 feature를 모두 모아둔 후, 새로운 데이터의 patch와 기존의 feature 포인트들 사이의 최소 거리를 patch 단위 anomaly 스코어로 사용한다.
하지만 앞서 언급했듯이, 두 스케일의 feature extractor를 이용해 patch 당 두 개의 feature를 얻고, 이를 이용해 두 개의 anomaly map을 얻어냈을 텐데 이것은 어떻게 합칠까?
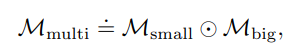
두 맵을 단순히 element-wise multiplication 함으로써 한 개의 anomaly 맵을 만들어낸다. 결국 small scale과 big scale의 feature를 이용한 SVDD 결과가 컨센서스를 이뤄 내야 최종적으로 anomalous한 patch라 결론짓는다는 의미이다. 위의 식과 아래의 사진을 참고하자.
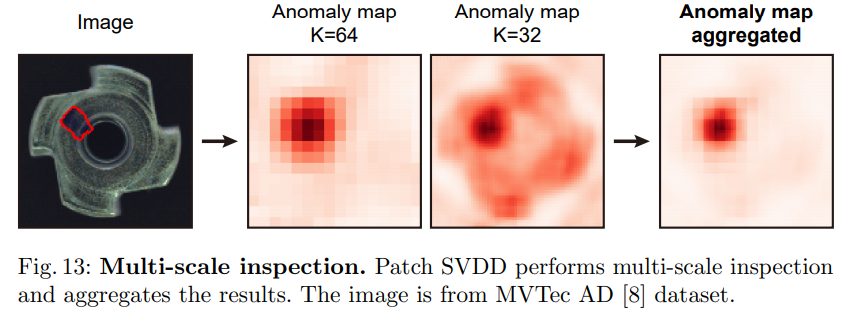
마지막으로, 이미지 단위의 anomaly score로는 anomaly 맵을 spatial 한 방향으로 max operation을 취해 얻어낸 스칼라 값을 사용한다.
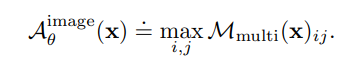
이제 결과를 보고 리뷰를 마무리 하자.
Results
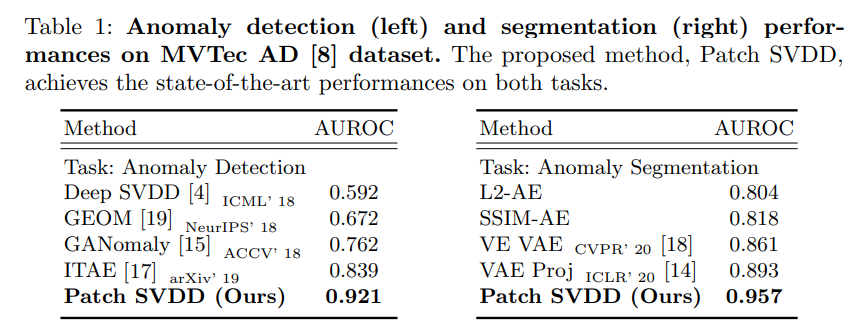
MVTec AD 데이터셋(1부 참고!) 을 사용해 anomaly detection 성능 벤치마킹을 했으며, 기존의 method들에 비해 꽤 좋은 성능을 보여준다. 여기서 쓰인 AUROC 메트릭도 1부를 참고해 주면 좋겠다.
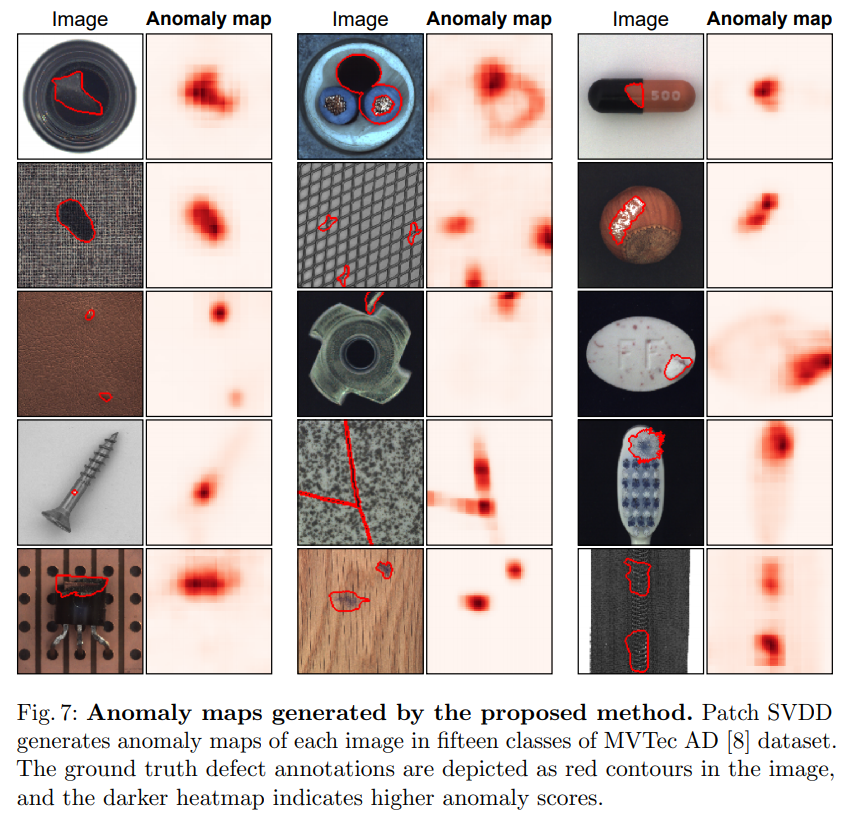
Patch-wise anomaly detection 방법론의 처음 의도대로, anomaly region에 대해 꽤 좋은 localization 성능을 보여주고 있는 것을 확인할 수 있다. Anomaly map의 resolution 자체는 엄청나게 높은 편은 아닌데, patch를 잘게 나눌 수록 evaluation 시간이나 학습 성능 쪽에서 tradeoff를 해야 하므로 resolution과 성능 사이에서 적절한 균형을 찾은 것으로 보인다.

또한 self-supervised learning task를 붙여 직접적인 성능 향상이 있었음을 리포트하고 있다. 위의 figure에서 $SVDD$가 기존의 Deep SVDD, $SVDD'$가 새로 제시된 Patch SVDD에 self-supervised learning(SSL)이 빠진 버전, 그리고 $SVDD+SSL$이 풀 버전 알고리즘을 의미한다.
특히 cable, transistor 데이터 class와 같이 텍스쳐 사진이 아니라 특정 object가 찍혀 있는 클래스들에서 특히 SSL의 효과가 컸는데, 논문에서는 multi-modal 데이터에 대한 feature extractor 학습에 SSL이 도움을 주고 있다고 주장한다.
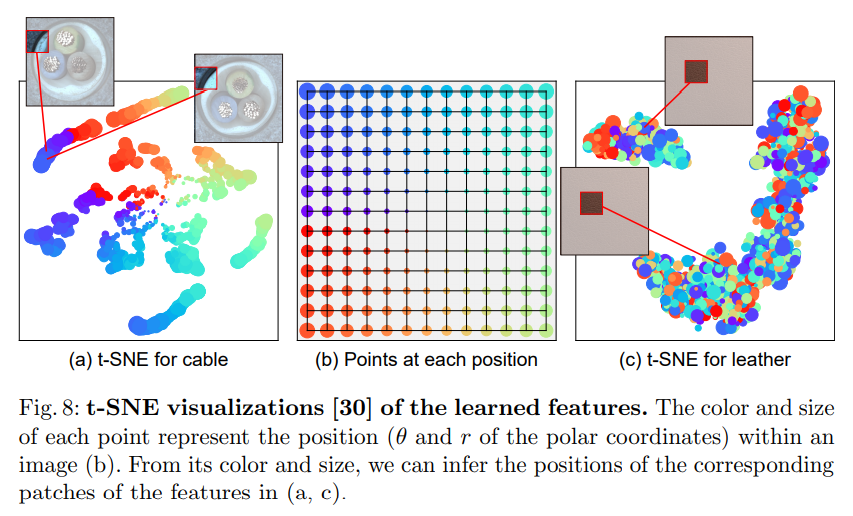
위에서 보듯이 전체적으로 patch의 appearance가 일정한 텍스쳐 사진들과 달리, foreground와 background가 명확한 오브젝트 사진들에서는 patch들이 특정한 몇 가지 mode를 가지고 있으며, 이는 학습된 feature를 visualize 했을 때 잘 나타나고 있다 (feature vector가 몇 개의 클러스터를 이루고 있다).

그리고 이런 patch의 multi-modality를 잘 학습할 수 있도록 돕는 것이 SSL 태스크임을 다시 실험적으로 검증하고 있다. 위 사진에서는 각 방법론을 이용해 학습해낸 feature 벡터를 visualize 하고 있는데, 맨 오른쪽의 SSL을 사용해 학습한 버전이 데이터의 multi-modality를 가장 잘 학습 했음을 정성적으로 보여주고 있다.
이 이외에도 multi-scale 방법론의 실효성이나, data의 intrinsic dimention을 통한 분석 등의 실험이나 다른 추가적인 디테일들이 남아있지만, 굵직한 내용들은 어느 정도 다룬 것 같다.
개인적으로는 마지막 실험 단계에서 방법론의 유효성을 검증하기 위해 다양한 실험 결과를 제공한 것은 굉장히 흥미로웠지만, 실험 결과에 미칠 효과를 구체적으로 예상할 수 없어 실험 결과로부터 역으로 파악해 내야 하는 요소들이 많았다는 점이 아쉽다. 특히 self-supervised learning을 이용하는 것에서 정확히 어떤 효과를 기대하며, 많은 SSL 태스크 중 relative position을 분류하는 문제가 어째서 선택되었는 지에 관한 고찰이 있었다면 훨씬 좋았을 것 같다.
아래는 참고할 만한 자료들이다.
References
SVDD 관련:
Deep One-Class Classification (Deep SVDD)
Support Vector Data Description (SVDD)
논문에서 쓰인 self-supervised learning 테크닉:
Unsupervised Visual Representation Learning by Context Prediction (ICCV 2015)
논문에서 쓰인 데이터셋:
MVTec AD: MVTec Software
Abstract MVTec AD is a dataset for benchmarking anomaly detection methods with a focus on industrial inspection. It contains over 5000 high-resolution images divided into fifteen different object and texture categories. Each category comprises a set of def
www.mvtec.com
